A Crowdin project at 100% looks the same whether the translations are excellent or just functional. Strings are filled. The release ships on time. RTL renders correctly in Arabic. From a pipeline perspective, the job is done.
From a user perspective, that’s only half the story.
There’s a category of localization problem that doesn’t show up in the workflow at all. It shows up three months later, in market performance data. Conversion in the UAE is lower than expected. Engagement in Korea is flat. The product hasn’t changed. The feature set is identical in every market. What changed is whether the localized experience actually lands for the people using it.
Shipping and performing are different problems. Most localization infrastructure is built to solve the first one, and does it well. The second one is a different kind of work.
The layer that sits above the workflow
Translation management systems do something genuinely difficult. Syncing files across teams, managing version control, enforcing terminology consistency, connecting to release cycles so nothing ships late. This is complex orchestration, and getting it right is a real achievement. Crowdin’s connectors, memory leverage, and workflow automation have made this layer significantly more accessible for product teams who would otherwise be managing it manually in spreadsheets.
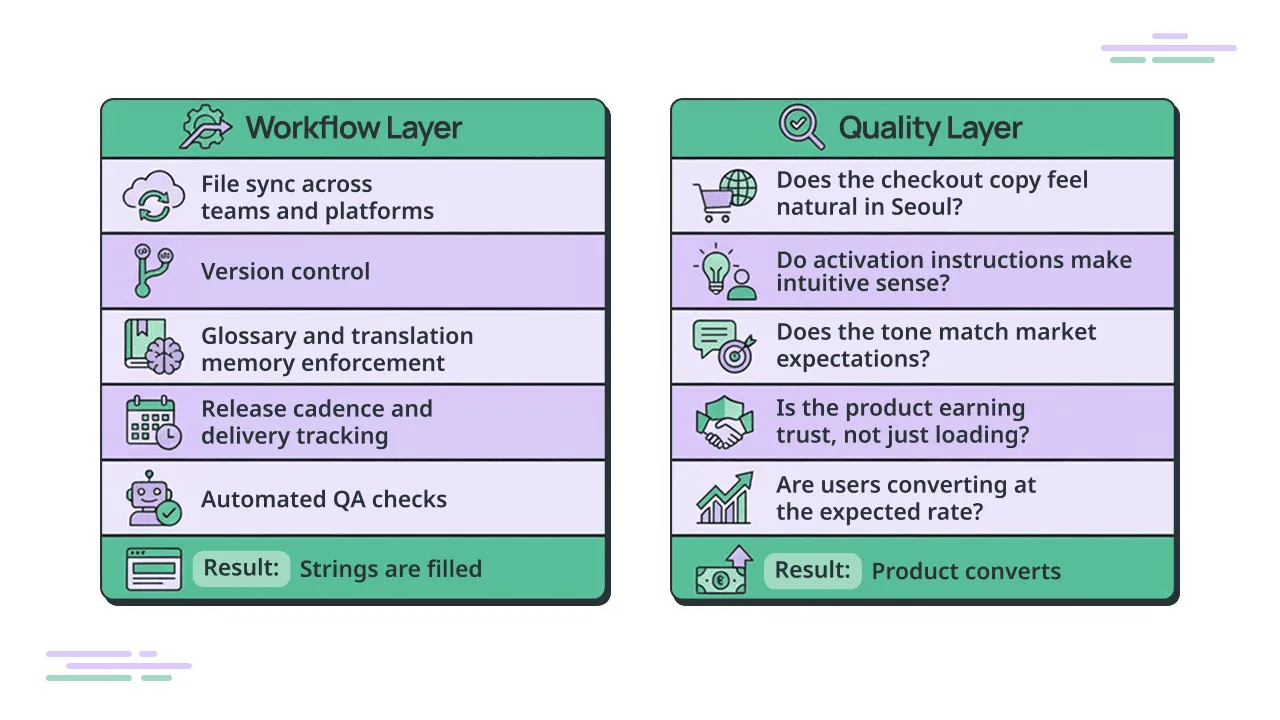
But there’s a layer above that. Whether the output of that workflow actually reaches users in a way that earns their trust, helps them understand the product, and moves them to act. That’s not a workflow question. That’s a user experience question.
A TMS can confirm that every string is filled and every glossary term was applied. It can’t tell you whether the checkout copy feels natural to a user in Seoul, or whether the activation instructions make intuitive sense to someone unfamiliar with your product category, or whether your notification copy reads as warm and helpful or stiff and foreign. Those are judgment calls. They require someone who can read the market, not just the file.
The good news is that getting this layer right is what makes everything else in the workflow pay off. Every hour invested in glossary consistency, memory leverage, and clean file delivery compounds in value when the end output is actually converting users. The infrastructure and the quality layer work together. One without the other leaves money on the table.
Why it hides
Localization KPIs are almost always compound. Conversion, retention, support ticket volume, app store ratings by region. These metrics don’t shift in clean lines that point to a single cause. When localization quality improves, the effect distributes across all of them at once. When it’s the problem, it looks like a market that’s just “underperforming” without an obvious explanation.
Product teams looking at flat numbers in a new market will first question the product, then the campaign, then the pricing. Localization quality is rarely the first hypothesis. And it shouldn’t be, because it isn’t always the answer. But it’s also rarely tested with the same rigor as the others.
There’s a structural reason for that. The people reviewing localized output usually can’t read it. The product manager, the QA team, the designer running the visual check. They’re looking for layout issues, truncation, broken UI elements. Those are real problems worth catching. But a string can be grammatically correct, properly formatted, and completely unnatural to a native speaker. It passes every automated check. It fails the user.
This is the gap the title points at. “Available in 11 languages” means strings are filled and the product ships. “Works in 11 languages” means a user in each of those markets has the same quality of experience as a user in the primary market. Getting from one to the other requires someone accountable for the outcome, not just the output.
Localization that doesn’t compile
There’s a useful parallel in software development. AI-generated code often looks right. The syntax is clean, the structure makes sense, it passes a visual scan. Then you run it and it breaks.
Localization has the same failure mode. Machine translation, or translation that’s rushed or under-briefed, produces output that looks like localization. The strings are filled. The file is complete. It moves through the workflow without a flag. Then it lands in front of a native speaker and something is wrong that they can’t quite name. The copy doesn’t feel like the product understands them. The checkout instructions are technically accurate but oddly phrased. The notification copy sounds like it was written for a different audience and redirected.
They don’t file a translation complaint. They bounce. They submit a support ticket about a “confusing” feature that isn’t broken. They leave a review saying the app feels unpolished. The localization didn’t compile in their heads, and the product pays for it in ways that take months to show up in the data.
What it looks like in practice
A global travel tech company was running a Crowdin-integrated localization program across 11 languages. Synced releases, glossary in place, ongoing updates tied to the product release cadence. By pipeline standards, the setup was solid.
Their baseline before investing in localization quality was a combination of machine translation and internal effort. For most of the product, it was enough to ship. For the parts where clarity directly affects behavior – the checkout flow, activation instructions, and app store descriptions, it wasn’t. Users were engaging but not converting at expected rates in several key markets. Support contacts were coming in from users who didn’t fully understand plan details or how to activate their product. The experience wasn’t landing.
Once Native Localization, a Crowdin Marketplace partner, identified and addressed quality gaps market by market, the compounding effect showed up across all the places localization KPIs live. Fewer support contacts from users confused by the product. Stronger trust signals in markets where the content now felt native. Faster campaign launches, because localization was running in parallel with the release cycle rather than scrambling to catch up.
None of those results point to a single metric at a single date. They’re compound, and they compound over time. That’s how localization outcomes work, and why the investment in getting the quality layer right pays back in multiple places simultaneously.
Where to look first
For product teams looking at underperforming markets and wondering whether localization quality is part of the picture, the diagnostic doesn’t require a full audit. A native-speaking reviewer with context about the product can assess a few hundred words of high-stakes copy and give a clear read on where the gaps are. Not a line-by-line check. A qualitative assessment: does this feel right, and where does it break down? The process of testing localized software when you don’t speak the language when you don’t speak the language is more structured than it sounds.
That kind of review tends to reveal patterns quickly. If the checkout copy is the problem, it’s usually the checkout copy across the board. If the tone is off, it’s usually off consistently. You don’t need to review everything to understand what needs attention.
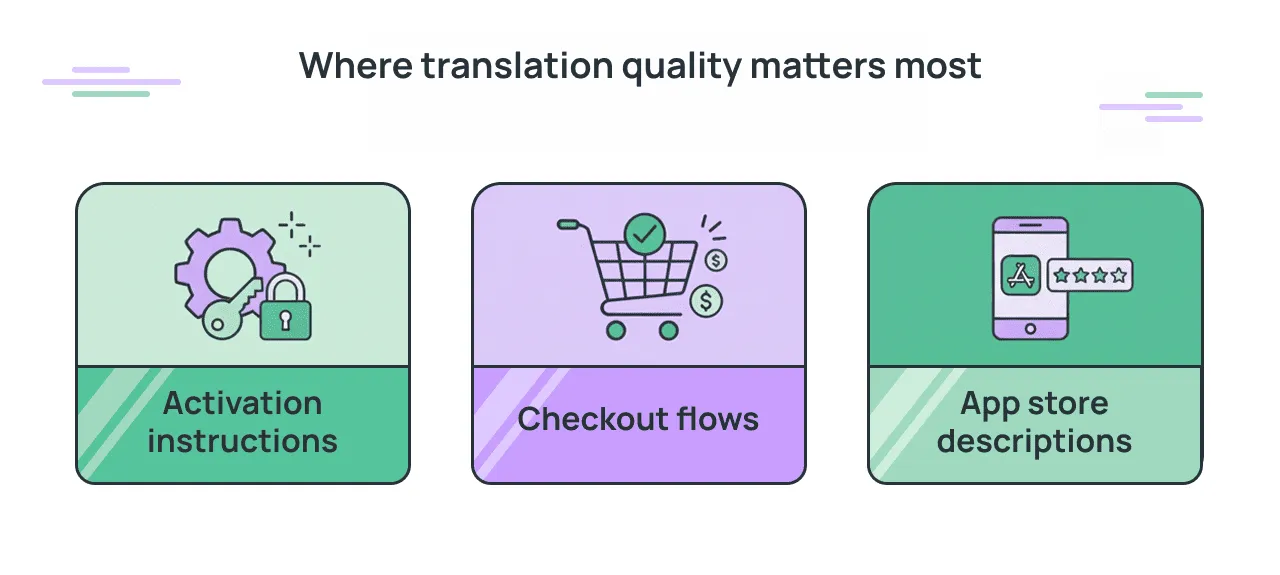
Checkout flows, activation instructions, and app store descriptions are the highest-leverage places to start. They sit closest to conversion and support volume. They’re also the content types where naturalness matters most, because a user who is uncertain at that moment has every reason to leave.
The goal isn’t to second-guess the workflow. It’s to close the loop between what ships and what converts. Every localization investment, from the TMS infrastructure to the translation itself, pays back more when that loop is closed.
The compounding effect
Teams that address the quality layer alongside the workflow layer describe a recognizable shift. Localization stops being a production task that runs behind the product and starts running alongside it. New market launches don’t require a remediation cycle after the fact. Campaigns go out across all languages at the same time. Support volumes in localized markets drop as the product actually explains itself to the people using it.
"The workflow gets you to “available”. The quality layer gets you to “works”.
The compounding effect is the part worth sitting with. Every month a market runs on localization that doesn’t land is a month of data collected from users who aren’t experiencing the actual product. When the gap closes, it changes the baseline that every subsequent decision gets made from.
Localize your product with Crowdin
Read more:
Didzis Grauss
Didzis Grauss is the founder of Native Localization, a localization agency specializing in SaaS, Fintech, E-commerce and iGaming. He has spent over a decade helping global consumer apps close the gap between shipping translations and performing in market, working across Crowdin, content management systems and custom localization stacks. He is a named Crowdin Expert and Native Localization is a Crowdin Marketplace partner.